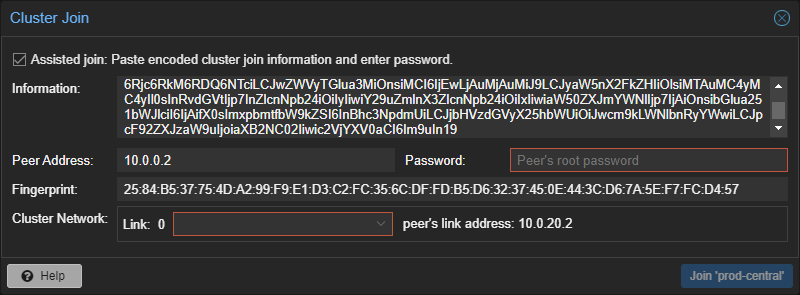
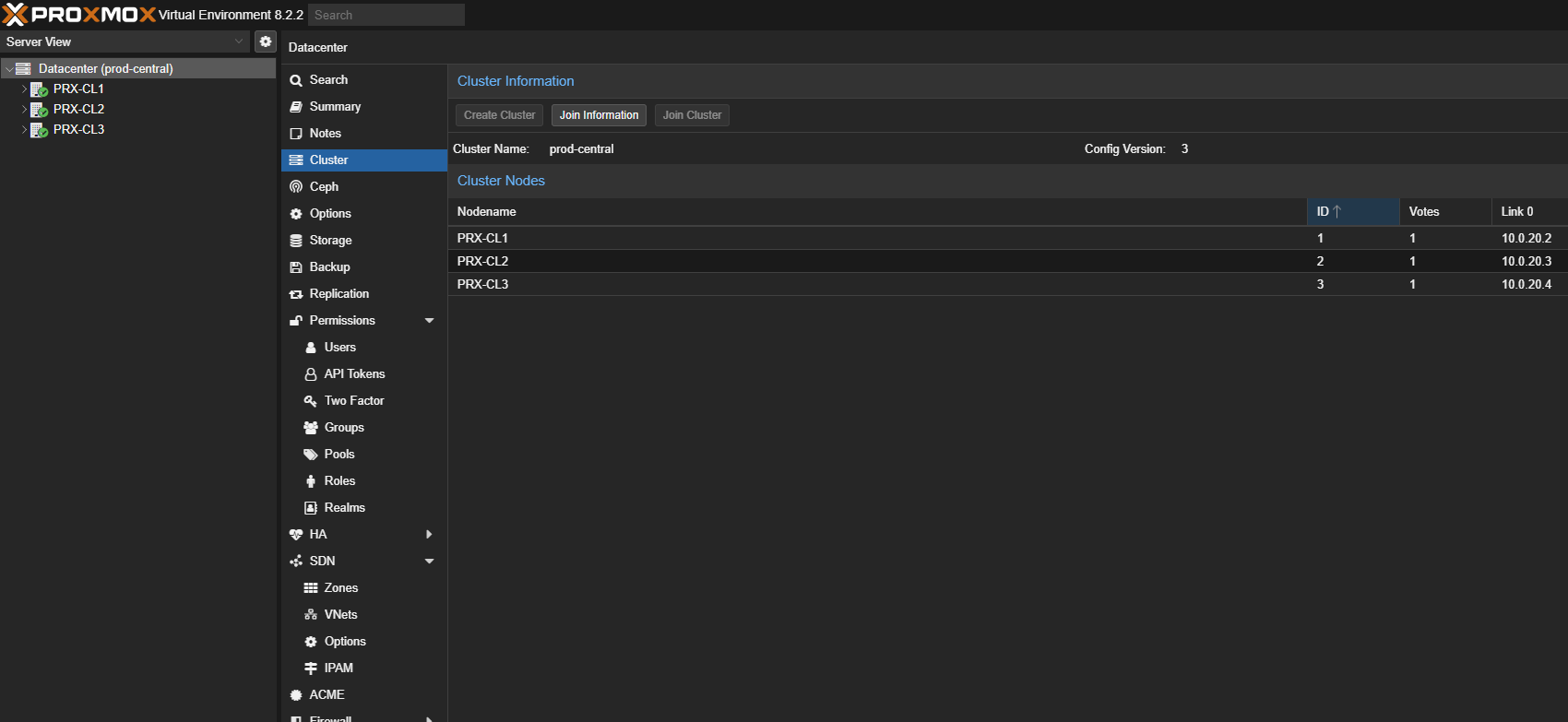
HA konfigurieren (Ab 3 Nodes)
Wie zuvor in dem Guide erwähnt, konfiguriere folgendes nur, wenn du 3 oder mehr Nodes im Cluster hast.
Ansonsten könntest du in das Split-Brain-Szenario laufen, welches zu inkonsistenten Daten führen kann.
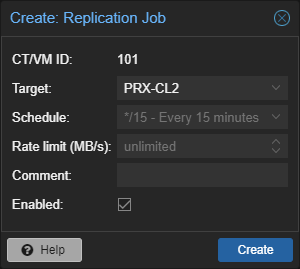
Bitte beachte, dass HA nur funktioniert, wenn du entweder eine funktionierende Replikation eingerichtet hast, oder einen geteilten Speicher benutzt (SAN).
Ressourcen hinzufügen
Klicke oben links auf Datacenter, und navigiere zu HA.
Du wirst sehen, dass keine Ressourcen für HA zugewiesen sind.
Für jede virtuelle Maschine solltest du HA konfigurieren.
Klicke Add und wähle eine virtuelle Maschine aus, welche du für HA konfigurieren willst.
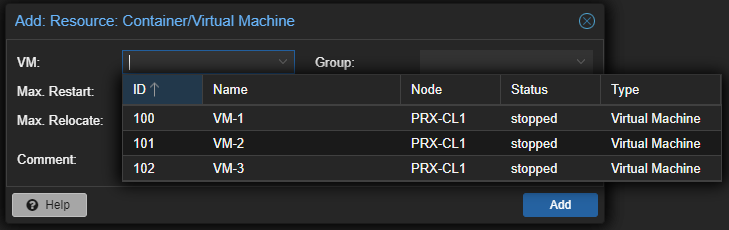
Du kannst Optionen einstellen, wie Max. Restart oder Max. Relocate.
Für die meisten Setups reichen die Standard-Optionen.
Max. Restart: Die maximale Anzahl an Versuche für einen Neustart auf einem Node, nachdem der Start fehlgeschlagen ist.
Max. Relocate: Die maximale Anzahl an Versuche für Verschiebungen, sollte der Start fehlgeschlagen sein.
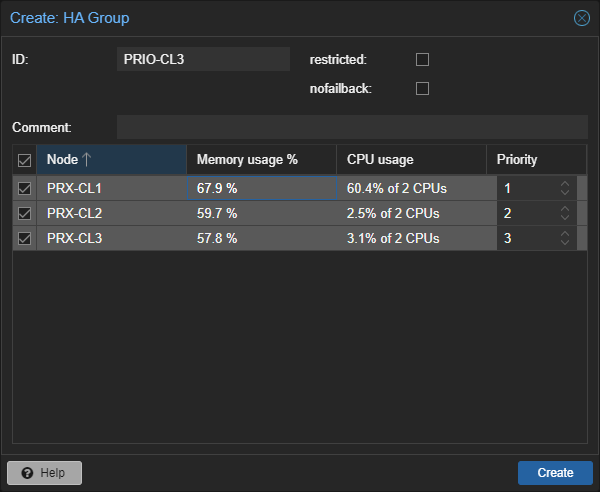
Gruppen
Mit Gruppen kannst du Zonen definieren, welche nur bestimmte Nodes beinhalten.
Du kannst eine Gruppe auswählen, wenn du HA für eine virtuelle Maschine konfigurierst.
Das wird dir auch erlauben, mit Prioritäten über verschiedene Nodes zu verteilen.
Behalte im Hinterkopf, dass wenn du eine höher Priorität zuweist, dass dieser Node dann benutzt wird. Lässt du den Node weg, wird der vermieden.
restricted: Diese Option erlaubt es zugeteilte Ressourcen auf jeden Node zu gehen, sollten alle Gruppen-Mitglieder Offline sein. Sie werden zurück-migriert, wenn ein Gruppen-Mitglied wieder online kommt.
nofailback: Mit dieser Option kannst du vermeiden, dass zurück-migriert wird, sobald ein Node wieder online kommt.
Hier ist ein Beispiel einer HA Gruppe, welche dem Node 3, die höchste Priorität gibt.
Vergewissere dich, dass du mindestens eine Replikation eingerichtet hast, oder ein SAN benutzt. Ansonsten wird der Failover nicht funktionieren, und möglicherweise musst du von Hand den vorherigen Zustand manuell wiederherstellen. (Siehe Fehler Sektion vom Guide).